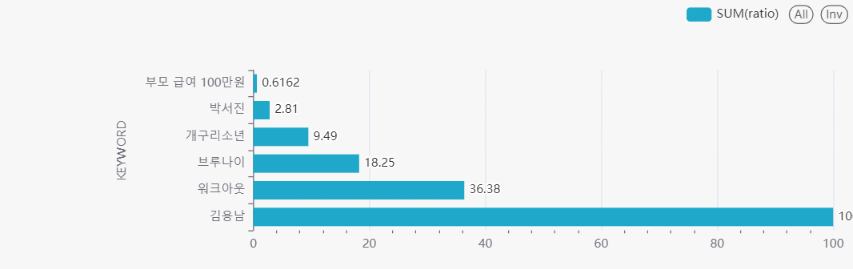
주제 구글 트렌드와 네이버 데이터랩을 이용하여 네이버 실시간 검색어 복원하기 구조 데이터 인프라 형성 구글 트렌드의 키워드 추출 네이버 데이터랩을 통해 검색어 순위 및 백분위 횟수 추출 이슈 구글 트렌드 공용 API 존재하지 않음 네이버 데이터랩 금일 데이터 존재하지 않음 키워드 입력 개수 5개 제한 네이버 데이터랩 ID, PASSWORD Variables 설정 전체 및 성별별 데이터 적재 프로젝트 코드 API RAW_CODE.py import os import sys import pandas as pd from pandas import Timestamp from datetime import datetime import urllib.request import json client_id = "id" cli..