강의
Spark
- 메모리 기반 혹은 디스크 사용
- 다수의 분산 컴퓨팅 환경 지원 : YARN, K8s, Mesos
- 판다스 데이터프레임과 유사
- 다양한 방식의 컴퓨팅 지원 : 배치 데이터, 스트림 데이터, SQL, 머신러닝, 그래프 분석
Spark 3.0 구성
- Spark Core
- Spark SQL
- Spark ML
- Spark MLlib
- Spark Streaming
- Spark GraphX
모듈
- API
- RDD (Resilient Distributed Dataset) : 세밀한 제어 가능 → 코딩 복잡도 증가
- DataFrame & Dataset : 하이레벨 프로그래밍 API. Spark SQL 혹은 Spark ML 사용
- Spark SQL
- SQL을 이용하여 구조화된 데이터 처리
- Hive 쿼리보다 최대 100배 빠른 성능 보장
- Spark ML
- 머신러닝 관련 알고리즘, 유틸리티를 포함한 라이브러리
- 데이터프레임 기반
- 원스톱 ML 프레임워크 : Spark SQL → Spark ML → ML Pipeline → MLflow
- 대용량 데이터 처리 가능
- Spark MLlib
- RDD 기반
사용 예시
- 대용량 비구조화된 데이터 처리 : ETL 혹은 ELT
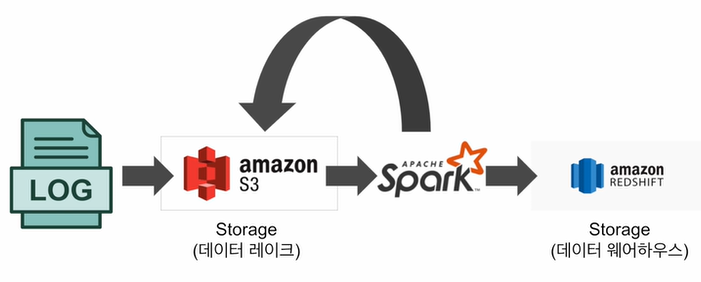
- ML 모델에 사용되는 대용량 피쳐 처리 : 배치 혹은 스트림

- Spark ML을 이용한 대용량 훈련 데이터 모델 학습
실행 환경
- 개발/테스트/학습 환경 (Interactive Clients)
- 노트북 : 주피터, 제플린
- Spark Shell
- 프로덕션 환경 (Submit Job)
- spark-submit (command-line utility)
- 데이터브릭스 노트북
- REST API : Spark Standalone 모드
구조
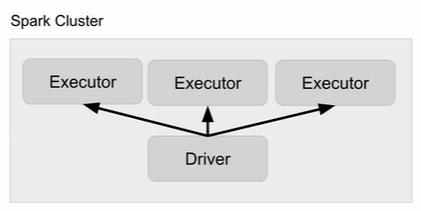
- Driver : 실행되는 코드의 마스터 역할 (YARN의 Application Master)
- 실행 모드(client, cluster)에 따라 실행되는 장소 변경
- 코드 실행에 필요한 리소스 지정
- 사용자 코드를 Spark 태스크로 변화나여 Spark 클러스터에서 실
- Executor : 실제 태스크 실행 역할 (YARN의 컨테이너)
- JVM : Transformations, Actions
- Cluster Manager (YARN의 Resource Manager)
- local[코어의 수]
- Client 모드 : 개발/테스트용
- YARN
- Client 모드 : Driver가 Spark 클러스터 밖에서 동작. 개발/테스트용
- Cluster 모드 : Driver가 Spark 클러스터 안에서 동작. 프로덕션 운영
- Kubernetes
- Mesos
- Standalone
- local[코어의 수]
'데브코스 TIL > 빅데이터, 스트리밍 데이터 처리' 카테고리의 다른 글
| Spark 설치 및 테스트 (0) | 2024.01.17 |
|---|---|
| Spark 데이터 처리 (0) | 2024.01.17 |
| Map Reduce 프로그래밍 (0) | 2024.01.15 |
| Hadoop 소개 및 설치 (0) | 2024.01.15 |
| 빅데이터 소개 (0) | 2024.01.15 |